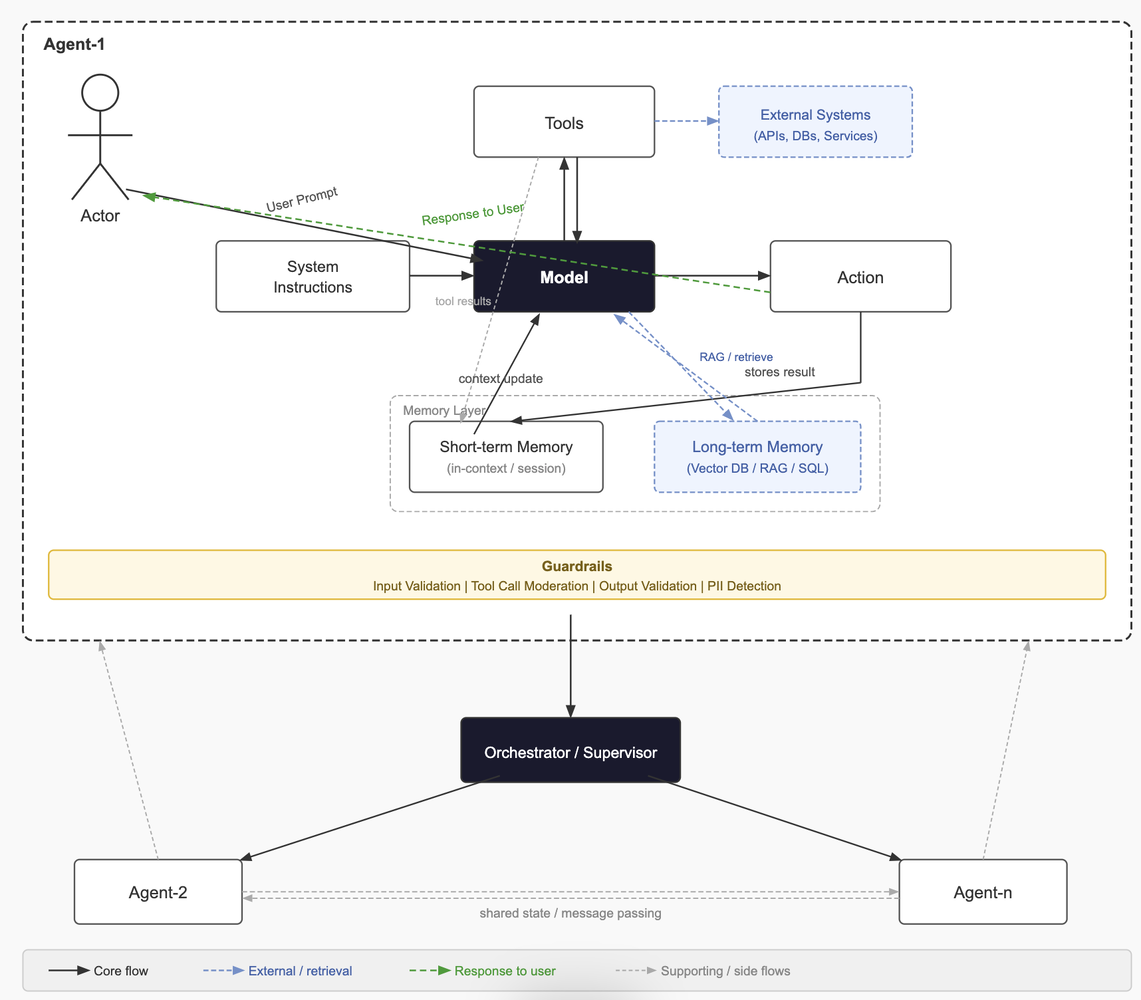
The first thing to get right is orchestration. Context has to flow from one workflow to another seamlessly. Agents should perceive input, analyse it, and then produce an output or trigger an action. That's the fundamental loop everything else is built around. Unlike traditional automation, agents are expected to handle ambiguity, recover from failures, and make decisions mid-execution.
Agentic Use-Cases
When it comes to types of agents, you've got software agents driving automated workflows, physical agents like robots operating through sensors, and hybrid agents like IoT devices that straddle both worlds. Rule-based systems are worth calling out explicitly because they are NOT agents. They're deterministic, there's no reasoning happening. Knowing when to actually reach for an agent matters: if your logic isn't binary, if you're depending on multiple systems, and if continuity of state is required, that's when an agent starts making sense. If a simple decision tree solves it, don't reach for an agent.
Models and Latency
The model is the heart of the agent, so choose it carefully. Don't pick a frontier model by default. Match capability to task complexity. GPT-4o or Claude Opus for complex reasoning, smaller models like Haiku or GPT-4o-mini for high-frequency simpler tasks. Think about latency too. Sync tasks like real-time user interactions have very different tolerances than async background jobs, and your model choice directly affects this. Cost is real, don't burn dollars where a smaller or fine-tuned model does the job. Always ask how much context your task actually needs because stuffing irrelevant context into a large window increases cost and can actually degrade model performance.
Tools
Tools are what give the LLM its ability to act. These are function-calling interfaces the model uses to take actions, whether internal APIs, databases, or external services like Polygon for market data or Stripe for payments. Vague tool definitions are one of the most common reasons agent behaviour goes unpredictable. The flow looks like this: a user prompt hits the instructions layer, the model forms a plan, tools get invoked (sometimes in parallel, sometimes sequentially depending on dependencies), an output or action is produced, and then memory and context get updated, feeding back into the next model plan. Error handling and retry logic inside this loop is critical for anything running in production.
Memory
Memory is what separates a capable agent from one that feels like it has amnesia. Short-term memory lives in-context within a session, often managed as a sliding window to stay within token limits. Long-term memory persists across sessions via relational databases or vector stores like Pinecone or pgvector for semantic retrieval. External memory pulls in knowledge through retrieval-augmented generation (RAG), knowledge bases, or live API calls. Getting this right means the LLM isn't re-querying from scratch every turn and can build on prior context instead. A very common mistake is treating memory as an afterthought. It should be considered from day one.
Orchestration
Orchestration patterns are where it gets interesting. A single agent takes input, calls tools, and makes decisions solo, which is fine for contained tasks. Multiple tool calling means the model loops through tool calls iteratively, gathering information until it has enough to produce a final answer, and this is how most function-calling agents operate today. ReAct, which you see in Claude Code, LangGraph, and similar systems, is a step-by-step Reason and Act loop where the model explicitly reasons before each action, making it more interpretable and easier to debug. Plan and Execute separates planning from execution entirely. The model produces a full plan upfront, then a separate executor runs each step, which works well for complex multi-step tasks where mid-execution replanning is expensive. Then you've got multi-agent coordination where specialised agents collaborate with a supervisor or router orchestrating between them. Frameworks like AutoGen and CrewAI are built around this. Decentralised patterns go further, with agents coordinating peer-to-peer through shared state or message passing, with no central orchestrator as a single point of failure.
Guardrails
Guardrails are something you should not skip. You can apply them at input, during tool calling, or at output, and ideally you're doing all three. Contextual guardrails keep the model on task and prevent scope drift. Safety and moderation filters handle abusive or policy-violating prompts before they hit the model. Llama Guard and NeMo Guardrails are worth knowing here. PII detection makes sure sensitive data doesn't leak through the pipeline. Output validation ensures what comes out is structured, safe, and semantically correct before it surfaces to a user or downstream system. Don't just validate format, validate intent. The tradeoff is real though. Too aggressive and you get over-blocking, added latency, and user friction. Guardrail design is a calibration problem, not a checkbox.
System Challenges
The real challenges you'll run into building agentic systems are system latency, model cost, making the right sync vs async architecture calls, designing memory that works at scale, and caching strategy. Semantic caching with something like GPTCache can cut costs significantly. But the biggest one is knowing when an LLM is genuinely the right tool versus when a deterministic function would be simpler, faster, and more reliable. Not everything needs an agent. The best agentic systems use LLMs exactly where reasoning is needed and step aside everywhere else.
If you're enjoying this post, consider subscribing to get future articles delivered straight to your inbox.
Subscribe